

目录
快速导航-

方法与技术 | 基于特征层融合的EEG-NIRS识别方法研究
方法与技术 | 基于特征层融合的EEG-NIRS识别方法研究
-

方法与技术 | 云原生应用开发与部署面临的挑战及其应对方案
方法与技术 | 云原生应用开发与部署面临的挑战及其应对方案
-

方法与技术 | 面向车联网的智能网联云控平台研究
方法与技术 | 面向车联网的智能网联云控平台研究
-

方法与技术 | 基于区块链的量子密钥分发在云存储的应用研究
方法与技术 | 基于区块链的量子密钥分发在云存储的应用研究
-

方法与技术 | 一种改进的Swin Transformer图像分类识别方法
方法与技术 | 一种改进的Swin Transformer图像分类识别方法
-

方法与技术 | 基于LBP和注意力机制的改进VGG网络的人脸表情识别方法
方法与技术 | 基于LBP和注意力机制的改进VGG网络的人脸表情识别方法
-

工具与环境 | 面向直播的边缘计算任务卸载方案研究
工具与环境 | 面向直播的边缘计算任务卸载方案研究
-

工具与环境 | 海空集群对抗深度强化学习算法研究平台设计
工具与环境 | 海空集群对抗深度强化学习算法研究平台设计
-

过程与模型 | 改进的容量约束设施区划模型的算法及应用
过程与模型 | 改进的容量约束设施区划模型的算法及应用
-

人工智能 | 基于改进多目标模板匹配在铝材计数的应用
人工智能 | 基于改进多目标模板匹配在铝材计数的应用
-

人工智能 | 基于机器学习的儿童颅骨畸形分类研究
人工智能 | 基于机器学习的儿童颅骨畸形分类研究
-

人工智能 | 基于5CV-Optuna-LightGBM回归模型的数据预测方法
人工智能 | 基于5CV-Optuna-LightGBM回归模型的数据预测方法
-

人工智能 | 基于UNet+Swin-Transformer的西瓜叶片病害识别的研究
人工智能 | 基于UNet+Swin-Transformer的西瓜叶片病害识别的研究
-

人工智能 | 基于用户反馈和对话历史的对话式推荐技术研究
人工智能 | 基于用户反馈和对话历史的对话式推荐技术研究
-
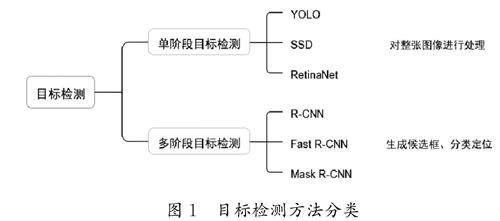
人工智能 | 基于YOLOv7的人体关联实时吸烟目标检测方法
人工智能 | 基于YOLOv7的人体关联实时吸烟目标检测方法
-

人工智能 | 基于BERT-LDA 和K-means聚类的绘画作品价值评估指标体系构建
人工智能 | 基于BERT-LDA 和K-means聚类的绘画作品价值评估指标体系构建
-

人工智能 | 基于改进YOLOv5s-pose的多人人体姿态估计
人工智能 | 基于改进YOLOv5s-pose的多人人体姿态估计



















 登录
登录